

ChatGPT und Konsorten basieren auf „schwacher KI“.
Dies ist bereits der zweite Beitrag zum Thema künstliche Intelligenz auf diesem Weblog:
In einem vorausgehenden Post ging es um Erfahrungen im Rahmen eines intensiven Tests von ChatGPT.
Ergebnis war: Legen wir tatsächlich als Standard menschliches Denken und menschliche Möglichkeiten zugrunde, rationale Überlegungen einzusetzen, zeigt sich die Beschränktheit aktueller KI-Applikationen.
Die mit statistischen Algorithmen arbeitenden „Elektronenhirne“ sind beispielsweise nicht in der Lage, für Menschen konzipierte Rationalitäts-Tests korrekt zu lösen. Logisches Schlussfolgern beherrscht das System höchst unvollkommen.
Als Fazit kann festgehalten werden:
Wer ChatGPT fest genug „schüttelt“, stößt schnell auf grundlegende Mängel der AI-Technologie. Verlässlich lassen sich damit lediglich leidlich gut klingende „Bullshit-Texte“ produzieren, deren Wahrheitsgehalt ungenügend ist.
Aber wer wundert sich über dieses Testresultat? Schließlich handelt es sich um ein vorhersagbares Ergebnis. Das Hintergrundwissen von Experten, die sich nicht – wie die breite Öffentlichkeit – von den aktuellen KI-Werbekampagnen in die Irre leiten lassen, werden durch die Beobachtungen mangelhafter AI-Fähigkeiten ein weiteres Mal bestätigt.
Warum das so ist?
ChatGPT macht wie gesehen unweigerlich Fehler, wenn es um logisches Denken, kritisches Hinterfragen oder kreative Problemlösung geht. Das hängt damit zusammen, dass diese Software ein Beispiel für eine sogenannte „schwache KI“ ist. Die dahintersteckende Technologie ist lediglich tauglich, recht spezifische Aufgaben zu erfüllen – im Fall von ChatGBT: Texte zu generieren.
„Starke KI“ in weiter Ferne
Diese Form schwacher KI ist nicht in der Lage, über ihren eigenen Zweck oder ihre eigenen Fähigkeiten nachzudenken, zu lernen oder sich anzupassen. Sie ist also nicht „intelligent“ nach menschlichen Maßstäben. Sondern es ist ein Programm, das nicht mehr kann, als bestimmte vorgegebene Regeln zu befolgen und auf einen Pool von Texten anzuwenden, anhand derer es „trainiert“ wurde.
Dies ist ein Faktum, das viele interessierte Laien, die seit Jahrzehnten per Science-Fiction-Literatur und Raumfahrtabenteuer-Kinofilmen mit fantastischen Visionen über die zukünftigen Möglichkeiten „Künstlicher Intelligenz“ bearbeitet wurden, aktuell tief enttäuschen wird. Immer wieder wurden auch im Feuilleton breitstreuender Medien großartige zukünftige „Maschinen-Denk-Leistungen“ versprochen.
Hintergrund ist, dass die verbreitete Vision zukünftiger Maschinen-Intelligenz „beseelt“ ist von der Vorstellung einer „starken KI“. Im Augenblick angeboten werden stattdessen mit ChatGBT und Konkurrenzprodukten lediglich Applikationen mit „schwacher KI“.
Bei der sagenhaften „starken KI“ handelt es sich um eine bisher lediglich „hypothetische“ Form der KI. Das bedeutet: Diese ideale „künstliche Intelligenz“ wurde bisher nicht realisiert.
Bisher gibt es nur die Hoffnung, dass Technologen irgendwann in der Lage sein werden, ihren Maschinen-Intelligenz-Traum zu erfüllen. Dazu müssten sie eine Maschinen-Kompetenz realisieren, die über ein selbständiges allgemeines Verständnis der Welt verfügt, das sich selbst verbessern kann.
Starke KI wäre in der Lage, jede Aufgabe zu erfüllen, die ein Mensch erfüllen kann, und vielleicht sogar mehr. Starke KI wäre also tatsächlich „intelligent“ und vielleicht sogar mit Bewusstsein ausgestattet.
Aber: Bisher gibt es keine starke KI und viele Experten (siehe Beitrag in diesem Blog) bezweifeln, ob sie grundsätzlich möglich ist.
Warum wird menschliches Denken auf der Basis der Computertechnik von heute kaum zu simulieren sein? Vergleichen wir zur Beantwortung dieser Frage die Leistungsfähigkeit der beiden unterschiedlichen Systeme:
Die biologische Intelligenz ist ihrer Konkurrenz aus Silizium beispielsweise weit voraus, wenn es darum geht, verallgemeinerte Konzepte aus Beobachtungen abzuleiten, aus wenigen Beispielen spontan zu lernen oder einmal gelerntes Wissen auf neue Bereiche zu transferieren.
Worin liegen die Ursachen für diesen Unterschied in der Verallgemeinerungs-Kompetenz?
Ursache 1: Bauplan für Denk-Mechanismen nicht vorhanden
Offensichtlich sind beide Systeme völlig unterschiedlich aufgebaut und zusammengesetzt: Das Gehirn als Organ hat sich im Laufe der Millionen von Jahren andauernden biologischen Evolution entwickelt. Die darin ablaufenden Denkprozesse greifen auf „Mindware“ zurück – Logik, Sprache, Philosophie, Mathematik, vielfältige fiktionale Konstrukte usw. – , die im Rahmen einer bereits viele Jahrtausende ablaufenden sozial-kulturellen Evolution entwickelt und per Sozialisation von einer auf die andere Generation von denkenden Menschen weitergegeben und fortentwickelt werden. In menschlichen Denksystemen – Hirnen – ist die biologische Hardware (beispielsweise der menschliche Cortex) und seine Software bzw. Mindware eine untrennbare Einheit und gut aufeinander abgestimmt.
Im Vergleich dazu ist ein Mikrochip zwar flexibel einsetzbar. Dieser müsste, um mit dem menschlichen Denken vergleichbare Prozesse nachzuvollziehen, die im Gehirn auf chemischer oder physischer Ebene selbstgesteuert ablaufenden Mechanismen Schritt für Schritt simulieren.
Es gibt im Augenblick keine Aussicht darauf, dass dies in näherer Zukunft gelingt. Denn es gibt ein Grundproblem: Die aktuelle neurowissenschaftliche Forschung ist längst nicht so weit, die in den Neuronen-Geflechten unseres Gehirns wirkenden Mechanismen technologisch reproduzierbar zu entschlüsseln, geschweige denn, einen Bauplan für ein Silizium-Hirn zu liefern.

Menschliches Denken wird voraussichtlich nicht auf der Basis von Silizium-Technologie zu simulieren sein. (Niek Doup aus Unsplash)
Ursache 2: Digitale Programme und neuronale Mechanismen sind nicht kompatibel.
Es gibt einen weiteren – grundlegenden – Unterschied zwischen Gehirn- und Silizium-Technik, der mit den unterschiedlichen „Programmierungen“ zu tun hat, mit denen Gehirne auf der einen und Computer auf der anderen Seite arbeiten:
Die heutige „künstliche“ Intelligenz von „Elektronen-Gehirnen“ arbeitet – einfach ausgedrückt – mit vorwärts gerichteten Netzwerken (euphemistisch als „neuronale Netze“ bezeichnet), bei denen Informationen Schicht für Schicht linear verarbeitet werden. Demgegenüber arbeiten die Neuronen im menschlichen Gehirn alles andere als linear. Typisch für menschliche Bewusstseins-Prozesse ist, dass die in den Hirnen zugrundeliegenden Mechanismen mit vor- und zurücklaufenden Interaktions-Impulsen arbeiten, um beispielsweise Vorhersageschleifen zu realisieren.
Die renommierte kanadische Neurowissenschaftlerin und Psychologin Lisa Feldman Barrett von der Northwestern University in Boston, Massachusetts, hat die dahinter steckenden Abläufe auch für Laien vereinfacht erläutert:

Lisa Feldman Barrett
(https://commons.wikimedia.org/wiki/File:Lisa_Feldman.jpg
TED talk, CC BY 4.0 <https://creativecommons.org/licenses/by/4.0>, via Wikimedia Commons)
In ihrem im Jahr 2017 erschienenen Bestseller „How Emotions are made.“, der Mitte des Jahres 2023 schließlich auch auf Deutsch erscheint, beschreibt sie, wie unser Gehirn laufend damit beschäftigt ist, unsere Welt zu simulieren. (Paperback-Ausgabe: Barrett, 2018, S. 56-83)
Dabei nehmen Neuronen an Vorhersageschleifen mit anderen Neuronen teil, wobei ganze Gehirnregionen an den Vorhersageschleifen gemeinsam mit wiederum anderen Regionen teilnehmen. Diese Vorhersageschleifen bilden einen durchgängigen parallelen Prozess, der während unseres gesamten Lebens kontinuierlich und ununterbrochen andauert. Jeden Augenblick wird dadurch unsere Welt-Konstruktion mit Geräuschen, Gerüchen, mit Geschmack sowie Berührung, Gefühlen und Denkabläufen realisiert und damit der Bezugsrahmen erzeugt, in dem wir unsere Handlungen platzieren.
Diese Simulationen werden laufend mit dem sensorischen Input aus der Welt außerhalb unseres Bewusstseins verglichen. Wenn Simulation und Input übereinstimmen, sind unsere Vorhersagen korrekt und unsere Simulation wird zu unserer Erfahrung. Stimmen sie nicht überein und hat unser Gehirn Vorhersagefehler gemacht, setzt es unmittelbar dazu an, aufgrund der Vorhersage-Abweichung revidierte Vorhersagen zu erzeugen.
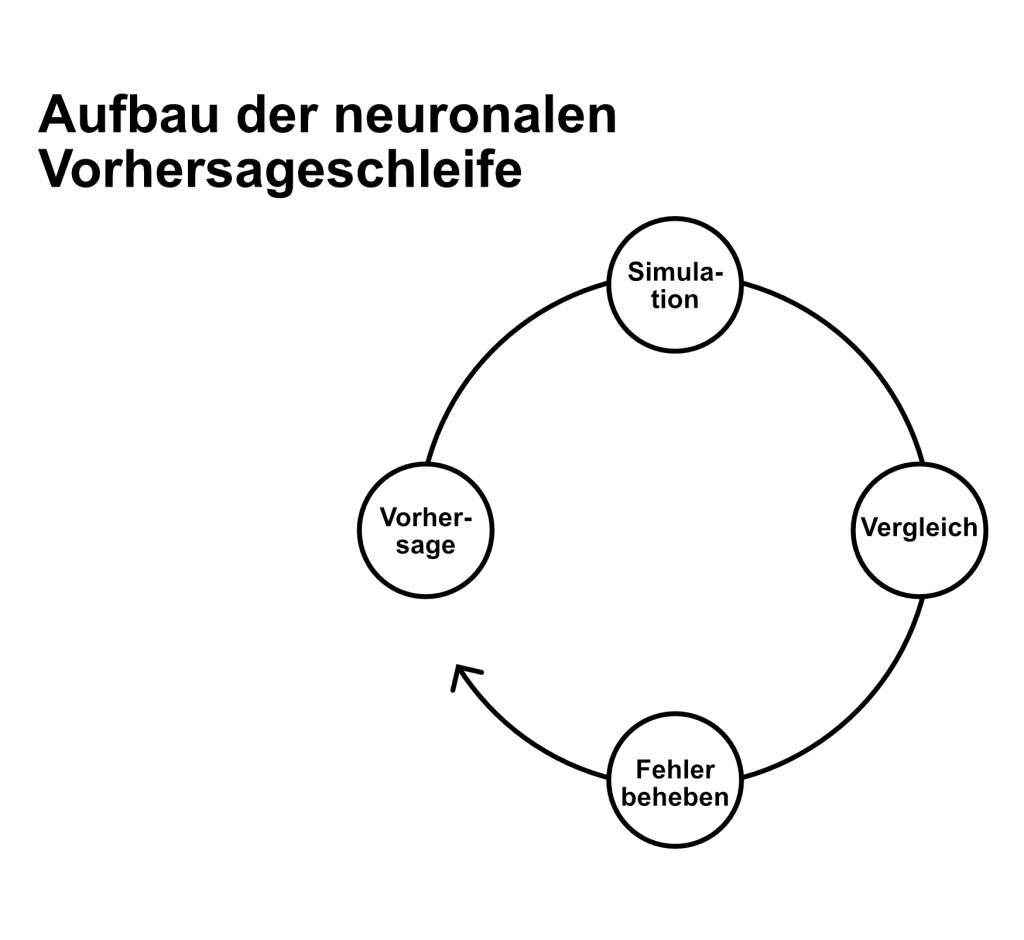
(Abbildung adaptiert und übersetzt: Grafik aus Barrett 2018 „Structure of a prediction loop“ Figure 4-2 – Droste 2022, S. 157)
Lisa Feldman Barrett bringt diese Analyse der Arbeit unserer Gehirne auf den Punkt, indem sie zur Metapher des Wissenschaftlers greift, der versucht, die Welt zu erklären.
(Barrett, 2018, S. 56 – 83 – Droste 2022, S. 157-158)
Bewusstseinsvorgänge basieren auf „prädiktiven“ Hirnprozessen
Wie ein Wissenschaftler stellt unser Gehirn ständig eine Reihe von Hypothesen auf. Wie dieser Wissenschaftler nutzt unser Hirn Wissen bzw. frühere Erfahrungen, um abzuschätzen, wie sicher es sein kann, dass diese Hypothesen wahr sind. Unser Gehirn testet anschließend seine Vorhersagen, indem es diese mit dem eingehenden sensorischen Input aus der Welt vergleicht – ähnlich wie ein Wissenschaftler Hypothesen mit aus einem Experiment stammenden Daten konfrontiert. Hat unser Gehirn eine gute Vorhersage zustande gebracht, dann bestätigt der Input aus der Welt unsere Vorhersagen. Fortwährend kommt es jedoch zu Vorhersagefehlern – schauen wir uns an, wie unser Gehirn entsprechend einem mehr oder weniger gewissenhaften Wissenschaftler gleichend höchst unterschiedlich auf diese Fehler reagieren kann:
- wie ein verantwortungsbewusster Wissenschaftler kann unser Gehirn seine Vorhersagen ändern, um auf aktuellen sensorischen Inhalt zu reagieren
- oder sich wie ein besonders neugieriger Wissenschaftler verhalten und sich insbesondere auf sich ändernden Input konzentrieren
- aber wie ein voreingenommener Wissenschaftler kann unser Gehirn von dem „realistischen“ Ideal abweichen und lediglich selektiv aus-schließlich die Daten aus dem sensorischen Input auswählen, die zu seinen Vorhersagen passen und die Weltsicht dadurch verzerren
- oder sich sogar wie ein skrupelloser Wissenschaftler verhalten und Überprüfungs-Daten ignorierend behaupten, seine Vorhersagen wären bereits die Realität
- oder sich wie der sprichwörtliche Lehnstuhl-Gelehrte oder „Geisteswissenschaftler“ verhalten und lediglich Ideen-Experimente durch-führen, um sich eine Welt vorzustellen, die er jenseits des sensorischen Datenstroms projiziert. Dieses Gehirn produziert eine „reine“ Simulation ohne sensorischen Input oder „störende“ Vorhersagefehler
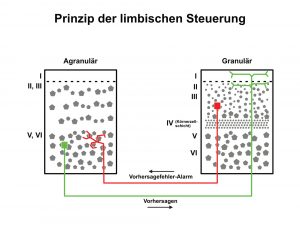
(Prinzip der limbischen Steuerung – mit Hilfe des Modells der limbischen Steuerung versuchen Neurowissenschaftler nachzuvollziehen, wie neuronalen Mechanismen des Gehirns die prädiktive Kodierung in der neuronalen Architektur des Cortex realisieren – Droste 2022, Abbildung 42 – adaptierte Grafik aus Barrett 2017, S. 8 – Figure A)
Statt Computer: „Hosenscheißer“ sind die ultimativen Lernmaschinen.
Wie deutlich sich vor diesem Hintergrund Hirnprozesse von der Arbeitsweise heutiger KI-Applikationen unterscheiden hat wiederum eine Psychologin in den USA für die breite Öffentlichkeit gut nachvollziehbar dargestellt. Es handelt sich um die Arbeiten von Alison Gopnik, u.a. als international renommierte Entwicklungspsychologin Professorin an der University of California, Berkeley, und Fellow der Cognitive Science Society, Seattle.

Alison Gopnik
(https://commons.wikimedia.org/wiki/File:Alison_Gopnik_Photo.jpg
Kathleen King, CC BY-SA 3.0 <https://creativecommons.org/licenses/by-sa/3.0>, via Wikimedia Commons)
Sie hat als Kolumnistin des Wallstreet Journals im Jahr 2019 einen interessanten Artikel zu unserem Thema veröffentlicht: Hier zeigt sie typische Vorzüge des frühkindlichen Lernens auf, indem sie es mit Computer-gestützter „Künstlicher Intelligenz“ (KI) konfrontiert: „The Ultimate Learning Machines“ („Die ultimativen Lernmaschinen“ – 11. Oktober 2019): (Gopnik, 2019)
Gopnik analysiert, wie IT-Wissenschaftler versuchen, künstliche „Intelligenz“ zu schaffen, indem sie bestimmte Algorithmen „maschinellen Lernens” bzw. des „machine learnings” nutzen. Computer werden in die Lage versetzt, „selbst“ herauszufinden, wie sie auf Basis der Daten, die ihnen präsentiert werden, optimal reagieren können. Diese Vorgehensweise hat zu scheinbar erstaunlichen Durchbrüchen geführt. Zum Beispiel wurden maschinelle Lernsysteme mit Millionen von Tierbildern aus dem Internet konfrontiert, von denen beispielsweise zahlreiche Fotos als Katzen- oder Hunde-Abbildungen gekennzeichnet worden waren. Ohne etwas anderes über Tiere zu wissen, konnten die Computer-Systeme die statistischen Muster in den Bildern extrahieren und dann diese Muster verwenden, um neu hinzukommende Beispiel-Fotos von Katzen und Hunden zu erkennen und zu klassifizieren. Mit maschinellen Lernsystemen wie Alpha Zero von Google Deep Mind konnten IT- Wissenschaftler einen Computer von Grund auf darauf trainieren, ein Videospiel, Schach oder das strategische Brettspiel “Go” zu spielen. Dem Computer wurde dabei jeweils als Bewertungskriterium eine Punktzahl angegeben, die durch eine bestimmte Spielaktion erreicht wird; nachdem er viele Millionen Spiele gespielt hat, lernt er schließlich, wie er diese Punktzahl maximieren kann, ohne dass er explizit über die Strategien von Schach oder Go informiert wurde.
Das Problem ist, dass dieser Algorithmus an erheblichen Grenzen leidet. „Elektronenhirne”, die damit arbeiten, benötigen enorme Datenmengen, um erfolgreich zu werden. Zudem benötigen sie dazu Daten von spezieller Qualität, und sie sind nicht sehr gut darin, auf der Basis dieser Daten zu verallgemeinern. Denn Künstliche Intelligenz erfordert, was Informatiker „supervision” – „Überwachung” – nennen. Um zu lernen, muss jedes Bild, das einem künstlich intelligenten Computer vorgelegt wird, mit einer Bezeichnung (z.B. „Hund”, „Katze”) versehen werden – jeder gescannte Spielzug eines Spiels muss zusammen mit einer Punktzahl dokumentiert werden.
Dagegen verarbeiten Säuglinge und Kleinkinder ihre Sinnesdaten weitgehend unbeaufsichtigt. Eltern sprechen dem Baby gegenüber vielleicht gelegentlich den Namen des Tieres aus, das gerade durch den Garten läuft, oder sagen „gut gemacht”, wenn es eine bestimmte Aufgabe erfüllt. Eltern kommentieren nicht jeden Anblick, der den Augen ihrer Kleinen geboten wird. Stattdessen sorgen Eltern vor allem dafür, ihre Kinder per rechtzeitigem Füttern und Wechseln der Windeln bei Laune zu halten und dadurch von ersten existentiellen Notlagen zu erlösen.

(Bild – Nahib Sohrabi auf Unsplash)
Was kleine Kinder lernen, lernen sie meist spontan und selbstmotiviert.
Die Daten, mit denen die Kleinen dabei konfrontiert sind, sind ganz anders, als die optimierten Bilder, mit denen Künstliche Intelligenz gefüttert wird. Alison Gopnik verweist in diesem Zusammenhang auf Forschungen von Kollegen. So haben Linda Smith von der Indiana University und Michael Frank von der Stanford University Kleinkinder mit superleichten Kopfkameras – sozusagen mit Baby-Action-Kameras – ausgestattet. Dabei zeigte sich, dass das, was Babys sehen, ganz anders ist als die Millionen von klaren Fotos in einem Internet-Datensatz, die in Computern eingelesen werden. Stattdessen zeigen die Kameras der Kleinkinder vereinzelte, chaotische und schlecht gefilmte Videos von ein paar vertrauten Dingen – Bällen, Spielzeug, Eltern, Katzen und Hunden -, die in seltsamen Perspektiven erscheinen.
KI-Bilderkennung ist fehleranfällig.
Insgesamt zeigt sich, dass Computer mit vielen kontrollierten Daten auf der Basis ihrer KI-Algorithmen nicht die gleichen Verallgemeinerungen machen können wie menschliche Kinder. Ihr Wissen ist viel enger und begrenzter und zudem lässt sich Künstliche Intelligenz schnell durch simple „Gegenbeispiele” täuschen. So wird ein KI-Bilderkennungssystem automatisch behaupten, dass es sich bei einem durcheinandergewürfelten Pixelhaufen um einen Hund handelt, selbst wenn die betreffende Pixelabfolge lediglich zufällig in das statistische „Hunde-Muster” passt. Solch ein Fehler unterläuft keinem Baby, das im Fall eines Hundes ein lebendiges Wesen vor sich sieht, statt statistisch zu analysierende Informationen.
Offenbar ist es das grundlegende Erfolgsgeheimnis von Babys, dass ihre Gehirne mit chaotischen Daten arbeiten, aber dennoch präzise Konzepte bilden und nutzen können. In diesem Zusammenhang wurde an der Universität Berkeley das Akronym MESSY gebildet: Model-Building, Exploratory, Social Learning System. Zutreffend, denn offenbar sind Kleinkinder tatsächlich kleine MESSYs – Modell-bildende, explorative soziale Lernsysteme.

(Bild: Andy Kelly via Unsplash)
Aus der Perspektive des Vergleichs mit IT-Systemen zeigt sich, wie erfolgreich die Fähigkeiten sind, über die Kleinkinder durch die Modell- und Theoriebildung ihrer Gehirne verfügen. Zwar können sie mit Hilfe dieser Mindware im ersten Lebensjahr noch nicht lernen, Schach zu spielen. Aber sie entwickeln bereits vernünftige Ideen über Physik und Psychologie. Es konnte gezeigt werden, dass schon einjährige Babys viel über physikalische Objekte wissen. Sie stutzen, wenn ihnen in einem Film ein in der Luft schwebendes und durch die Wand fahrendes Spielzeugauto präsentiert wird.
Auch über Mitmenschen und ihre Absichten wissen Babys etwas. So konnte gezeigt werden, dass Einjährige, die sehen, dass einer Person versehentlich ein Stift auf den Boden fiel, diesen aufheben und der Person bringen. Und sie tun dies nicht, wenn die Person den Stift absichtlich auf den Boden geworfen hat.
Ein weiterer entscheidender Faktor, der Kinder von Künstlicher Intelligenz unterscheidet, ist laut der Psychologin Alison Gopnik die Art und Weise, wie sie von anderen Menschen sozial lernen. Kultur ist unsere Natur, und sie macht unser Lernen besonders leistungsfähig. Jede neue Generation von Kindern kann von allem Wissen profitieren, das frühere Generationen entdeckt haben.
Fazit: ChatGPT ist lediglich ein „Content-Synthesizer“.
Kommen wir zum Fazit, nachdem wir heutige KI-Applikationen anhand des Anspruchs bewertet haben, Kompetenzen zu entwickeln, die menschlichem Denken nahekommen oder diesen sogar überlegen sind.
Zwar können Computer mit Hilfe von Software verblüffend schnell Datenmaterial statistisch auswerten und auf dieser Basis ab jetzt Texte generieren.
Sie können Wissen zusammenfassen und sammeln – statt es tatsächlich selbst zu schaffen. Die verwendeten Algorithmen realisieren Techniken zur Weitergabe von in Datenbanken abgespeicherten Informationen von einer Gruppe von Menschen an eine andere.
Die Möglichkeiten dieser Techniken sind begrenzt – die Schaffung eines Maschinen-Menschen ist eine zumindest im Augenblick unrealisierbare (Horror-)-Vision.
ChatGPT kann nicht leisten, was intelligente und rationale Menschen leisten können. Es handelt sich bestenfalls um eine Kulturtechnologie, verwendet um Texte und Inhalte bis zu einer gewissen Qualitätsstufe zu produzieren.
Möglicherweise wäre der Umgang mit Applikationen wie ChatGPT einfacher, würde in ihrer Bezeichnung direkt signalisiert, was die Kulturtechnologie tatsächlich kann: Statt von Künstlicher Intelligenz – KI- oder Artificial Intelligence -AI – könnten wir beispielsweise von „Content-Synthesizern“ sprechen. Dadurch wird deutlicher, dass diese Systeme lediglich Formulierungs-Vorschläge machen, die vor Verwendung von einem menschlichen Bediener gründlich geprüft und zu verantworten sind.
Quellen
- Barrett, L. F. (2017). The theory of constructed emotion: An active inference account of interoception and categorization. Social Cognitive and Affective Neuroscience, 12(1), 1–23. https://doi.org/10.1093/scan/nsw154
- Barrett, L. F. (2018). How emotions are made: The secret life of the brain (Paperback edition). PAN Books.
- Droste, H.W. (2022 ). RQ – Entfessele Dein bestes Denken. Pedion Verlag
- Gopnik, A. (2019, Oktober 11). The Ultimate Learning Machines. Wall Street Journal. https://www.wsj.com/articles/the-ultimate-learning-machines-11570806023
Aufmacher-Bild: Foto Ahmed-al-Munther auf Unsplash



